手把手教你用Python获取最全NBA数据
作者:全直播 | 发表于:2023-04-09 | 阅读:165次
喜欢NBA的朋友可能知道有个非常全面和专业的NBA中文数据库--Stat-NBA

上面不仅有所有球队球员的各项数据,还统计了从NBA创立的的1946年来的所有数据,还是中文版本的,还可以通过各种筛选进阶数据。但如果想要下载来自己分析,就比较麻烦。今天就专门写一个python如何获取stat-nba数据的教程,并用工具做一个简单的动态变化图。视频效果:
01 选取数据说到NBA数据,很多人首先想到的是得分榜,那今天我们就拿历年来的得分榜前10数据。
http://www.stat-nba.com/season/1946.HTML

这个页面可以获取到每个赛季的各项排行榜,而且重点是URL非常友好,使用的后缀是年份,这样我们只需要遍历所有年份的URL即可。
02 基本思路1.将要获取的目标网页的html源码保存起来;2.再使用etree进行提取页面element,etree.HTML()可以用来解析字符串格式的HTML文档对象,将传进去的字符串转变成_Element对象。作为_Element对象,可以方便的使用getparent()、remove()、xpath()等方法;3.将获取到数据按照要求格式保存到dataframe中;4.最后使用花火在线生成动态图工具使用的第三方包括:requests,lxml中的etree,pandas
03 流程与代码# 再使用etree进行提取页面element,etree.HTML()可以用来解析字符串格式的HTML文档对象,将传进去的字符html = etree.HTML(html)print(type(html))print(html) # 使用html.xpath()提取指定标签的文本内容,xpath标签获取方式,可以在谷歌浏览器中,比如在上图的”乔福尔克斯“上面右键,# 选择copy-》copy xpath,即可得到://*[@id="allpts0"]/div[1]/div[1]/aplayer = html.xpath('//*[@id="allpts0"]/div[1]/div[1]/a')[0].textprint(player)
# 使用html.xpath()提取指定标签的文本内容,xpath标签获取方式,可以在谷歌浏览器中,比如在上图的”乔福尔克斯“上面右键,# 选择copy-》copy xpath,即可得到://*[@id="allpts0"]/div[1]/div[1]/aplayer = html.xpath('//*[@id="allpts0"]/div[1]/div[1]/a')[0].textprint(player)

获取到页面源码的element格式后,可以使用xpath轻松提前指定标签下的内容。从图中可以看出,得分榜的内容存放在一个div中,id=“allpts0"中,球员名称和数据存放在下面的div class='content'中,总共10个,那我们只需要把这10个标签下面的a和p标签内容获取到即可:
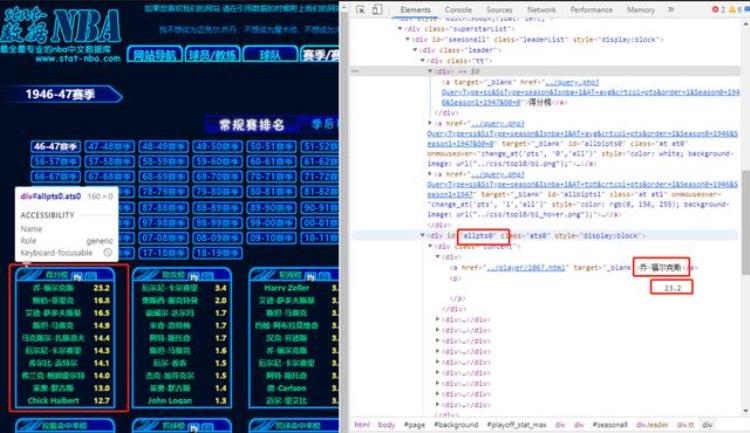 # 然后就可以将10个球员的数据都保存到字典rankrank = {}for i in range(1,11): player = html.xpath('//*[@id="allpts0"]/div[1]/div[{}]/a'.format(str(i)))[0].text data = float(html.xpath('//*[@id="allpts0"]/div[1]/div[{}]/p'.format(str(i)))[0].text.strip()) # 转化成数值 rank[player] = dataprint(rank)# 输出的格式:{'乔-福尔克斯': 23.2, '鲍伯·菲里克': 16.8, '艾德-萨多夫斯基': 16.5, '斯坦-马赛克': 14.9, '马克斯尔-扎斯洛夫斯基': 14.4, '厄尔尼-卡尔费里': 14.3, '库尔比-贡特尔': 14.1, '弗兰克-鲍姆霍尔特兹': 14.0, '莱奥-默古斯': 13.0, 'Chick Halbert': 12.7}# 然后就可以将10个球员的数据都保存到字典rankrank = {}for i in range(1,11): player = html.xpath('//*[@id="allpts0"]/div[1]/div[{}]/a'.format(str(i)))[0].text data = float(html.xpath('//*[@id="allpts0"]/div[1]/div[{}]/p'.format(str(i)))[0].text.strip()) # 转化成数值 rank[player] = dataprint(rank)# 输出的格式:{'乔-福尔克斯': 23.2, '鲍伯·菲里克': 16.8, '艾德-萨多夫斯基': 16.5, '斯坦-马赛克': 14.9, '马克斯尔-扎斯洛夫斯基': 14.4, '厄尔尼-卡尔费里': 14.3, '库尔比-贡特尔': 14.1, '弗兰克-鲍姆霍尔特兹': 14.0, '莱奥-默古斯': 13.0, 'Chick Halbert': 12.7}
# 然后就可以将10个球员的数据都保存到字典rankrank = {}for i in range(1,11): player = html.xpath('//*[@id="allpts0"]/div[1]/div[{}]/a'.format(str(i)))[0].text data = float(html.xpath('//*[@id="allpts0"]/div[1]/div[{}]/p'.format(str(i)))[0].text.strip()) # 转化成数值 rank[player] = dataprint(rank)# 输出的格式:{'乔-福尔克斯': 23.2, '鲍伯·菲里克': 16.8, '艾德-萨多夫斯基': 16.5, '斯坦-马赛克': 14.9, '马克斯尔-扎斯洛夫斯基': 14.4, '厄尔尼-卡尔费里': 14.3, '库尔比-贡特尔': 14.1, '弗兰克-鲍姆霍尔特兹': 14.0, '莱奥-默古斯': 13.0, 'Chick Halbert': 12.7}# 然后就可以将10个球员的数据都保存到字典rankrank = {}for i in range(1,11): player = html.xpath('//*[@id="allpts0"]/div[1]/div[{}]/a'.format(str(i)))[0].text data = float(html.xpath('//*[@id="allpts0"]/div[1]/div[{}]/p'.format(str(i)))[0].text.strip()) # 转化成数值 rank[player] = dataprint(rank)# 输出的格式:{'乔-福尔克斯': 23.2, '鲍伯·菲里克': 16.8, '艾德-萨多夫斯基': 16.5, '斯坦-马赛克': 14.9, '马克斯尔-扎斯洛夫斯基': 14.4, '厄尔尼-卡尔费里': 14.3, '库尔比-贡特尔': 14.1, '弗兰克-鲍姆霍尔特兹': 14.0, '莱奥-默古斯': 13.0, 'Chick Halbert': 12.7}
接下来,可以批量获取全部年份的得分榜数据
df = pd.DataFrame()for i in range(1946,2020): url = 'http://www.stat-nba.com/season/{}.html' url = url.format(str(i)) r = requests.get(url,verify=False) html = r.content.decode('utf-8') html = etree.HTML(html) rank = {} for j in range(1,11): player = html.xpath('//*[@id="allpts0"]/div[1]/div[{}]/a'.format(str(j)))[0].text data = float(html.xpath('//*[@id="allpts0"]/div[1]/div[{}]/p'.format(str(j)))[0].text.strip()) # 转化成数值 rank[player] = data print(rank) df = df.append(pd.DataFrame(index=[i],data=rank))最终的数据是:
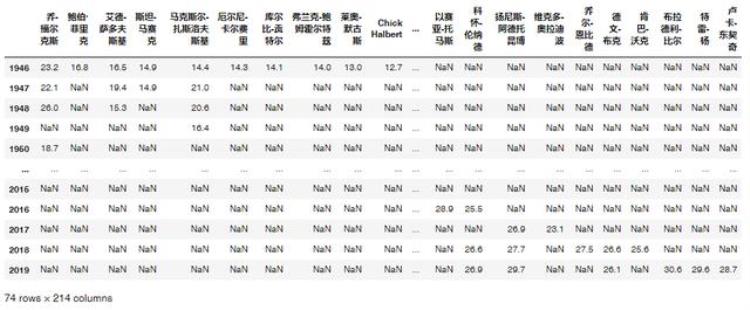
为了按照工具的数据格式要求,只需要稍微转置一下:
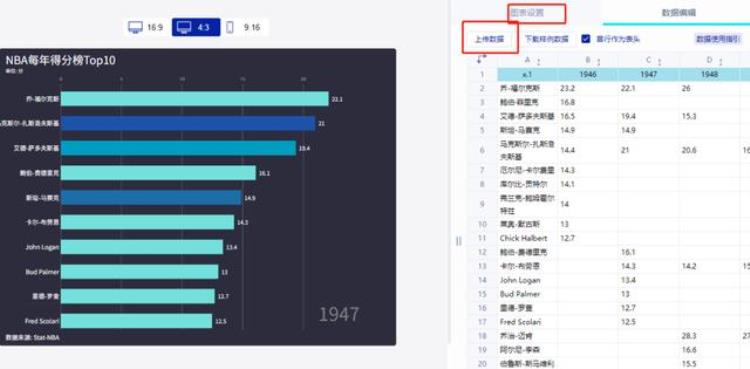
df.T.to_excel('ptsrank.xlsx','utf-8-sig')04 上传数据制作视频火花的URL:https://hanabi.data-viz.cn/templates
选择动态条形图即可。注:火花很多图表是付费的,免费的可以使用Flourish。
声明
1.本数据分析只做学习研究之用途,勿用他途,提供的结论仅供参考;
2.公开数据不建议抓取太多,以免对服务器造成负担,如有侵权,马上删除
特别声明:所有资讯或言论仅代表发布者个人意见,全直播仅提供发布平台,信息内容请自行判断。
相关资讯
-
 喜欢NBA的朋友可能知道有个非常全面和专业的NBA中文数据库StatNBA 上面不仅有所有球队球员的各项数据,还统计了从NBA创立的的1946年来的所有数据,还... (查看全文)2023-04-09 | 阅读:166次
喜欢NBA的朋友可能知道有个非常全面和专业的NBA中文数据库StatNBA 上面不仅有所有球队球员的各项数据,还统计了从NBA创立的的1946年来的所有数据,还... (查看全文)2023-04-09 | 阅读:166次
推荐阅读





热门阅读





热门标签更多+
全国 球员 德甲 足球赛 排球 足彩 消费者 冬奥会 美洲杯 红警 在这 KG 千万别 水平 MVP 果冻 独显 欧洲杯 刀塔2 原因 金球 安托万 汉化版 命中率 传奇 顺利 NBA2K20PC 意甲 我能 世纪 MyNBA 国足 修改器 带你 赛圆满 CBA 巴西 Mercurial 中文版 詹姆斯 女足 历史性 阿根廷 学校 传闻 乒乓球 预赛 而且 时候 春晚 马尔 专栏 丰厚 不离 小将 技巧 NBASF 篮球 NBAlogo 彩铃 英超 欧冠杯 男足 今日 巴萨 加拿大 科比 潮流 教你 踢足球 体育 时代 战争 赔率 火箭队 世界杯 全部 大巴 你知道 深夜 可畅玩 洛杉矶 网球 今天 CS:GO 斯诺克 非洲杯 凯文 欧冠 进球 少年 亚运会 足协杯 双色球 亚冠杯 西甲 理性 F1 韩国
- 特别声明:本站所有直播和视频均来自互联网,本站不从事任何经营业务,仅为体育爱好者提供免费赛事数据服务。备案号:苏ICP备19037501号 广告合作@huzhan6688